
Prosseguindo com a série de artigos sobre as arquiteturas dos chips gráficos, hoje vamos continuar tratando da microarquitetura Graphics Core Next - abreviada por GCN -, da AMD.
Neste momento já não me importo tanto em chamar de ATi / AMD, pois desde as Tera Scale a engenharia da AMD já estava comandando os projetos.
Se nas TeraScale a AMD não focava tanto em GPGPU, as GCN vieram pra mudar a situação da marca no mercado e fazer uma concorrência melhor frente ao 'olho verde'.
A GCN teve 5 gerações, sendo que três já foram tratadas no Capítulo 5, que pode ser acessado CLICANDO AQUI!
Vamos continuar da GCN 4.0...

As GPUs da família Artic Island foram introduzidas no segundo trimestre de 2016 com a série AMD Radeon 400. O mecanismo 3D, nomeado GCA (Graphics and Compute array) - também conhecido como GFX - é idêntico ao encontrado nos chips Tonga, no entanto, apresenta um controlador de exibição mais recente, UVD versão 6.3, etc.
Todos os chips baseados em Polaris, exceto o Polaris 30, são produzidos no processo FinFET de 14 nm, desenvolvido pela Samsung Electronics e licenciado para a GlobalFoundries. O Polaris 30 atualizado, um pouco mais recente, é construído no processo LP FinFET de 12 nm, desenvolvido pela Samsung e GlobalFoundries.

Imagem 1 - O die Ellesmere, comercialmente conhecido como "Polaris 20"
O conjunto de instruções GCN de quarta geração é compatível com a terceira geração, isto pois se trata de apenas uma otimização para o processo FinFET de 14 nm, permitindo velocidades de clock de GPU mais altas que a antecessora. As melhorias arquitetônicas incluem:
-> Novos agendadores de hardware;
-> Um novo acelerador de descarte primitivo;
-> Um novo controlador de exibição e um UVD atualizado que pode decodificar HEVC em resoluções de 4K a 60 quadros por segundo com 10 bits por canal de cor.
GPUs:
-> Polaris 10 (também codinome Ellesmere) encontrado em placas gráficas "Radeon RX 470" e "Radeon RX 480";
-> Polaris 11 (também codinome Baffin) encontrado em placas gráficas "Radeon RX 460" (também Radeon RX 560 D);
-> Polaris 12 (também codinome Lexa) encontrado nas placas gráficas "Radeon RX 550" e "Radeon RX 540";
-> Polaris 20, que é um Polaris 10 atualizado (processo LPP Samsung / GlobalFoudries FinFET de 14 nm) com clocks mais altos, usado para placas gráficas "Radeon RX 570" e "Radeon RX 580";
-> Polaris 21, que é um Polaris 11 atualizado (processo LPP Samsung / GlobalFoudries FinFET de 14 nm), usado para placas gráficas "Radeon RX 560";
-> Polaris 22, encontrado em placas gráficas "Radeon RX Vega M GH" e "Radeon RX Vega M GL" (como parte de Kaby Lake-G);
-> Polaris 23, que é um Polaris 12 atualizado (processo LPP Samsung / GlobalFoudries FinFET de 14 nm), usado para placas gráficas "Radeon Pro WX 3200" e "Radeon RX 540X" (também Radeon RX 640);
-> Polaris 30, que é um Polaris 20 atualizado (processo LP GlobalFoudries FinFET de 12 nm) com clocks mais altos, usado para placas gráficas "Radeon RX 590".
Além das GPUs dedicadas, a Polaris é utilizada nas APUs do PlayStation 4 Pro e Xbox One X, intituladas “Neo” e “Scorpio”, respectivamente.
Se você comparar com o diagrama de blocos na GCN 3.0 vai ver que muito pouco muda. Observe o esquema desde die Baffin:

Diagrama 1 - Um die Baffin esquematizado em blocos de hardware
Assim como na GCN 2.0 e 3.0, os agrupamentos de CUs continuam sendo chamados de "Shader Engine" (abreviado SE). Sendo 16 TMUs e 8 CUs em cada um dos 2 SEs do Baffin, há 64 Stream Processors em cada Unidade Computacional.
Tal qual na GCN 1.0, 2.0 e 3.0 - e diferente das arquiteturas da nVidia - a AMD manteve o bloco de saída de rasterização acoplado ao Shader Engine.
Observando o Diagrama 1, na saída de rasterização existem 2 blocos (abreviados no diagrama com "RB"), e neles são distribuídas:
-> As unidades Z-Stencil;
-> As Z-Stencil Cache (Z$);
-> 8 ROPs;
-> RGB Cache (ou Color Cache - C$).
Interligado com a Saída de Rasterização e com os Memory Controllers de VRAM, um grande bloco de cache L2. São 1024 kB de L2 no total. Os 2 controladores juntos garantem um barramento de dados de 128 bits.
Perceba que junto das unidades ACE há blocos HWS.
No die Havaí e em outras GPUs baseadas no Graphics Core Next 1.0, 2.0 e 3.0, o hardware foi projetado para suportar um número fixo de filas de computação (até 8 por ACE). No entanto, começando com GCN de 4ª geração, o HWS (Hardware Scheduler) torna possível virtualizar essas filas.
Isso significa que qualquer número de filas pode ser suportado e o HWS as atribuirá aos ACEs disponíveis à medida que os slots virtuais forem disponibilizados.
Cada bloco ACE no(s) diagrama(s) da Arquitetura GCN representa(m) um único despachante de frente de onda / grupo de trabalho. Consequentemente, a GPU Fiji e as GPUs baseadas na arquitetura Polaris podem enviar até quatro frentes de onda/grupos de trabalho para os mecanismos de sombreamento a partir de qualquer fila de computação a qualquer momento.
As unidades HWS são microprocessadores de tarefa dupla capazes de lidar com duas threads de agendamento e seu comportamento pode ser ajustado com atualizações de microcódigo por parte da AMD.
CURIOSIDADE: O HWS controla as unidades de computação e é capaz de reservar blocos de shader para tarefas específicas. A AMD usa isso para TrueAudio Next, porque o DSP (Digital Signal Processor) dedicado para som surround foi removido do chip. Em vez disso, por exemplo, oito blocos são endereçados por meio da API LiquidVR via Compute Unit Reservation.
CURIOSIDADE: Outra inovação da Polaris é o sombreamento de taxa variável, que pode renderizar viewports com diferentes resoluções. A ideia é semelhante ao Multi Res Shading da nVidia e é adequada para realidade virtual, especialmente com rastreamento ocular. A AMD revisou a unidade geométrica nos mecanismos de sombreamento: O Primitive Discard Accelerator descarta polígonos extremamente pequenos - que não podem ser vistos posteriormente na imagem - antes que as unidades de computação iniciem seu trabalho. Isto é relevante para tesselação, especialmente em combinação com antialiasing multisample.
Agora observe este die Ellesmere (Polaris 30):

Diagrama 2 - O die Ellesmere possui 4 GEs
Foram distribuídos 9 CUs em 4 agrupamentos denominados Shader Engine, totalizando 36 Unidades Computacionais, cada uma com 4 TMUs (144 no total) e 64 sombreadores (2304 no total).
Os Raster Blocks (RB) representam a saída de rasterização, onde residem as ROPs, unidades Z-Stencil, bem como as Z-Stencil cache (Z$) e Color Cache (C$).
Um detalhe interessante é que a quantidade de ROPs não é proporcional à quantidade de sombreadores, e, consequentemente de Unidades Computacionais, característica típica da GCN. Como os blocos RB são integrados aos Shader Engine, para cada um dos 4 há 8 ROPs, totalizando 32 no chip.
Uma CU da GCN 4.0 pode ser descrito da seguinte forma:

Diagrama 3 - Uma UC por dentro
Perceba que há muitas semelhanças com as Unidades Computacionais das gerações anteriores da GCN, bem como das posteriores detalhadas neste artigo.
A GCN 4.0 inclui quatro SIMDs, cada um com um arquivo de registro de 64 kB de VGPRs (registros de uso geral vetoriais) de 32 bits, para um total de 65.536 VGPRs por CU. Cada UC também possui um arquivo de registro de SGPRs (registradores escalares de uso geral) de 32 bits. Até o GCN 3.0, cada CU continha 512 SGPRs. Da GCN 3.0 adiante a contagem aumentou para 800. Isso resulta em 3.200 SGPRs no total por CU, ou 12,5 kB.
A menor unidade de trabalho agendado para uma Computer Unit executar é chamada de WaveFront (frente de onda). Um conjunto de frentes de onda forma uma Thread. Cada um dos quatro SIMDs da UC pode trabalhar com até 10 ondas simultâneas. A UC pode suspender uma onda e executar outra, enquanto aguarda a conclusão das operações de memória. Isso ajuda a ocultar a latência e a maximizar o uso dos recursos de computação.
O tamanho dos arquivos VGPR introduz um limite importante: os VGPRs do SIMD são divididos igualmente entre as ondas ativas que formam uma Thread. Se um shader exigir mais VGPRs do que os disponíveis, o SIMD não será capaz de executar o número ideal de ondas. A ocupação, isto é, uma medida do trabalho paralelo que a GPU poderia realizar em um período de tempo será prejudicada.
Cada CU GCN possui compartilhamento de dados locais (LDS - Local Data Share) de 64 kB. LDS é usado para armazenar os dados compartilhados em um conjunto de WaveFronts de Thread. O Direct3D limita a quantidade de dados compartilhados que um único grupo de frentes de onda pode usar a 32 kB. Portanto, é preciso executar pelo menos dois conjuntos em cada UC para utilizar a máxima capacidade do LDS.
A interface de memória na GCN 4.0 foi atualizada para aumentar a largura de banda e também operar de forma mais eficiente com compressão. O back-end de renderização foi projetado para compactar buffers de cores para economizar energia e usar com mais eficiência a largura de banda de memória disponível.
A compactação de cores Delta é um algoritmo sem perdas que divide dinamicamente um buffer de cores em vários blocos e foi implantado pela primeira vez em soluções GCN de 3ª geração (por exemplo, GPUs de codinome Tonga, Fiji e Antigua). Um único pixel em cada bloco é escrito usando uma representação normal e todos os outros pixels no bloco são codificados como uma diferença do primeiro valor. O tamanho do bloco é escolhido dinamicamente com base nos padrões de acesso e nos padrões de dados para maximizar os benefícios.
A taxa de compactação máxima é de 8:1 para um bloco de 256 bytes. Como muitos objetos possuem grandes manchas de cores semelhantes (por exemplo, roupas e carros), a compressão de cores Delta aproveita essa localidade para melhorar o desempenho. Enquanto o GCN de 3ª geração usam algoritmos semelhantes, o 4.0 é mais agressivo e comprime ainda mais blocos, economizando assim mais largura de banda e energia. A maior economia ocorre quando o buffer de cores é lido para cálculos subsequentes, ou seja, renderização no modo de textura. Os núcleos dos Shaders Engines podem ler e descompactar de forma transparente os dados de cores, economizando assim largura de banda de leitura na memória RAM e nos caches.

Gráfico 1 - Comparação entre placas de vídeo Radeon
O GCN 4.0 possui uma interface de memória compacta de até 256 bits para os modelos mais parrudos, e faz uso de memória RAM GDDR5, mas oferece desempenho final semelhante ao da GPU de codinome Havaí, que usava uma interface de 512 bits – e tudo isso consumindo menos energia.
Flip-Flop Multi-Bit (MBFF)
Os projetistas pegaram emprestada uma técnica conhecida como “flip-flops de vários bits" da CPU para economizar energia e aumentar o desempenho. Os flip-flops retêm temporariamente um único bit entre funções computacionais e entre diferentes estágios do pipeline e são um dos blocos de construção mais comuns em uma GPU. Por exemplo, uma UC Polaris contém aproximadamente 21 milhões de flip-flops. Cada um deles possui uma entrada de clock, entrada de dados, armazenamento e saída de dados.
A entrada do clock aciona o flip-flop para transitar seus dados armazenados para a saída e receber novos dados da entrada. Uma rede de clock percorre todo o chip, distribuindo este sinal que sincronizam a operação. Em operação ativa, a rede de clock normalmente consome cerca de 20 a 35% da energia total de um chip gráfico com arquitetura GCN 4.0.
A AMD desenvolveu os “quad-flops”, onde quatro flip-flops compartilham uma única entrada de clock mais forte. Um único quad-flop consome cerca de duas vezes mais energia em comparação com um flip-flop normal, mas realiza o trabalho de quatro flops – reduzindo a carga na rede de clock por um fator de dois, o que, por sua vez, economiza cerca de 5% do consumo total de energia da UC. Como benefício adicional, o quad-flop economiza uma pequena quantidade da área dentro do chip.
CODIFICAÇÃO e DECODIFICAÇÃO de VÍDEO
A arquitetura Polaris inclui a última geração de mecanismos de aceleração de codificação e decodificação de vídeo da AMD, ou seja, o Video Code Engine 3.1 ou 3.4 (VCE) e o Unified Video Decoder 6.3 (UVD, anteriormente chamado de "Universal Video Decoder"), respectivamente.
O acelerador de decodificação da arquitetura foi atualizado para lidar com o perfil HEVC/H.265 main10, com suporte para resolução de 3840x2160 em até 60 Hz com cores de 10 bits para o conteúdo HDR. A arquitetura GCN 4.0 também foi atualizada para incluir suporte para o Codec VP9 com resolução de até 4K, que se encaixa na transição do YouTube para a codificação VP9.
CURIOSIDADE: O bloco de hardware VCE da arquitetura GCN 4.0 é apenas uma "reestilização" feita no VCE 3.0 (utilizado na arquitetura GCN 3.0).
No lado da codificação, a aceleração da codificação H.264 é transportada de produtos da geração anterior a taxas de 1080p @ 120 Hz, 1440p @ 60 Hz ou 2160p @ 30 Hz. A AMD trabalhou com vários fornecedores de aplicativos — incluindo Plays.tv, AMD Gaming Evolved Powered by Raptr e OBS Studio — para expor essa funcionalidade. À medida que as plataformas e serviços de streaming fazem a transição para HEVC/H.265 para melhorar a qualidade e as taxas de dados, a arquitetura Polaris também foi atualizada para incluir aceleração de codificação H.265 nas taxas de 1080p @ 240 Hz, 1440p @ 120 Hz e 2160p @ 60 Hz.
A arquitetura Polaris também melhora a qualidade da codificação, permitindo taxa de bits variável em duas passagens. O acelerador de codificação de vídeo executa uma passagem de pré-codificação em uma cena reduzida que é analisada no nível do quadro e do macrobloco para determinar o orçamento eficiente da taxa de bits e a seleção do parâmetro de quantização (QP).
Os parâmetros de controle de taxa derivados desta análise são usados para orientar a codificação final, resultando em uma saída com menos artefatos gerais de macroblocos e uma fidelidade notavelmente maior. O modo de duas passagens aumenta a latência no pipeline de codificação, mas pode reduzir os requisitos de taxa de bits e melhorar os resultados finais para usuários que gravam seu jogo em disco.

A arquitetura GCN 5.0 trouxe avanços mais significativos, ao menos nos diagramas de blocos feitos para o marketing do produto!
No diagrama abaixo, observe parte do die Greenland (Vega 10):

Diagrama 4 - Diagrama de blocos do die Greenland
Com um tamanho de matriz de 495 mm³ e uma contagem de transistores de 12.500 milhões, Vega 10 oferece suporte a DirectX 12 (nível de recurso 12_1). Para aplicativos de computação GPU, o OpenCL versão 2.1 pode ser usado. Possui 4.096 unidades de sombreamento, 256 unidades de mapeamento de textura e 64 ROPs.
O processador gráfico “Vega” 10 possui 4 blocos Graphics Engine (GEs, destacado em amarelo no diagrama acima), cada um contendo 16 unidades de computação (CUs), totalizando 64.
Tal como na GCN 1.0, os agrupamentos de CUs voltaram a ser chamados de "Graphics Engine".
Cada CU possui 64 NCUs, o que lhe dá um total geral de 4.096 Stream Processors.

Diagrama 5 - Por dentro de cada Computer Engine
Perceba no diagrama acima que um CU é subdividido em 4 blocos, cada um com 16 Shaders. Um CU GCN 5.0 possui 4 unidades de saída de rasterização, que são genericamente definidas como "Pixel Engine".
Diferente das outras gerações da GCN, a AMD tornou o bloco de saída de rasterização acoplado a cada Computer Unit, e não mais acoplado ao Graphics Engine (ou Shader Engine).
Observando o Diagrama, na saída de rasterização existem 16 blocos (denominados no diagrama com "Pixel Engine"), e neles são distribuídas:
-> As unidades Z-Stencil;
-> As Z-Stencil Cache (Z$);
-> 1 ROP;
-> RGB Cache (ou Color Cache - C$).
Há apenas uma única ROP dentro de cada CU. Interligado com a Saída de Rasterização e com os Memory Controllers de VRAM, um grande bloco de cache L2. São 4 MB de L2 no total.
Embora essa contagem de unidades possa ser familiar às GPUs Radeon anteriores, a combinação de velocidades de clock mais altas e melhorias na arquitetura podem evoluir substancialmente o rendimento das instruções.
Na Radeon RX Vega64 Liquid Cooled Edition, esse array de shader NCU é capaz de 13,7 TeraFlops de taxa de transferência aritmética de precisão simples. Graças à sua facilidade para matemática compactada de 16 bits, esse mesmo array de shader pode atingir uma taxa de pico de 27,4 TeraFlops de taxa de transferência aritmética de meia precisão. Uma dinâmica semelhante se aplica a outras taxas gráficas importantes. Por exemplo, o pipeline de geometria de função fixa é capaz de quatro primitivas por clock de taxa de transferência, mas o sistema de geometria GCN 5.0 tem capacidade potencial muito maior, como explicaremos com mais detalhes abaixo.
Vega 10 é o primeiro processador gráfico AMD construído usando a interconexão Infinity Fabric, a qual também sustenta os microprocessadores Ryzen. Essa interconexão estilo SoC de baixa latência fornece comunicação coerente entre blocos lógicos no chip com recursos integrados de qualidade de serviço e segurança. Por ser um padrão da AMD, o Infinity Fabric permite adotar uma abordagem flexível e modular para o design da CPU. É possível misturar e combinar vários blocos IP para criar novas configurações que atendam às necessidades de aplicação. No Vega 10, o Infinity Fabric conecta o núcleo gráfico e os outros blocos lógicos principais do chip, incluindo o controlador de memória, o controlador PCI Express, o mecanismo de exibição e os blocos de aceleração de vídeo. Graças a esta tecnologia integrada em cada um desses blocos IP, as futuras GPUs e APUs tiveram a opção de incorporar elementos da arquitetura Vega à vontade.
As GPUs são processadores massivamente paralelos que exigem enormes quantidades de movimentação de dados para atingir o pico de rendimento. Eles contam com uma combinação de dispositivos de memória avançados e sistemas de cache multinível (em geral, L1 e L2) para atender a essa necessidade. Em um arranjo típico, os registradores para os vários elementos de processamento extraem dados de um conjunto de caches L1, que por sua vez acessam um cache L2 unificado no chip. O cache L2 fornece acesso de alta largura de banda e baixa latência à memória de vídeo dedicada da GPU.
Uma GPU geralmente exige que todo o seu conjunto de dados e recursos de trabalho seja mantido na memória de vídeo local, uma vez que a alternativa (ou seja, extrair os dados da memória do sistema host através de um barramento PCI Express) não fornece largura de banda suficientemente alta ou latência suficientemente baixa para mantê-lo funcionando com desempenho máximo. Os desenvolvedores experimentaram uma variedade de hacks para solucionar esse problema, mas a crescente complexidade do gerenciamento de memória do software representa um desafio assustador. Enquanto isso, o custo e a densidade da memória local restringiram de forma executiva o tamanho máximo dos conjuntos de dados gráficos. A arquitetura “Vega” rompe essa limitação ao permitir que sua memória de vídeo local se comporte como um cache de último nível.
Se a GPU tentar acessar um dado não armazenado atualmente na memória local, ela poderá puxar apenas as páginas de memória necessárias através do barramento PCIe e armazená-las no cache de alta largura de banda, em vez de forçar a GPU a parar enquanto todo o conteúdo faltante é copiado. Como as páginas normalmente são muito menores que texturas inteiras ou outros recursos, elas podem ser replicadas muito mais rapidamente. Assim que a transferência for concluída, quaisquer acessos subsequentes a essas páginas de memória se beneficiarão de menor latência, pois agora residem no cache. Esse recurso é possível graças a uma adição à lógica do controlador de memória chamada High-Bandwidth Cache Controller (HBCC). Ele fornece um conjunto de recursos que permitem que a memória remota se comporte como memória de vídeo local e a memória de vídeo local se comporte como um cache de último nível. O HBCC suporta endereçamento de 49 bits, fornecendo até 512 TeraBytes de espaço de endereço virtual. Isso é suficiente para cobrir o espaço de endereço de 48 bits acessível pelas CPUs modernas e é várias ordens de magnitude maior do que os poucos GigaBytes de memória de vídeo física normalmente anexados às GPUs atuais.
O HBCC é uma tecnologia revolucionária para servidores e aplicações profissionais. Tal tecnologia também pode ser aproveitada para aplicações de consumo, mas a principal limitação nesse espaço é que a maioria dos sistemas não terá o benefício de grandes quantidades de memória do sistema (ou seja, mais de 32 GB) ou da VRAM na placa gráfica. Neste caso, o HBCC estende especificamente a memória de vídeo local para incluir uma parte da memória do sistema. Os aplicativos verão essa capacidade de armazenamento como um grande espaço de memória. Se eles tentarem acessar dados não armazenados atualmente na memória local de alta largura de banda, o HBCC poderá armazenar em cache as páginas sob demanda, enquanto as páginas usadas menos recentemente serão trocadas de volta na memória do sistema. Esse pool de memória unificado é conhecido como "segmento de memória HBCC" (abreviado HMS).
CODIFICAÇÃO e DECODIFICAÇÃO de VÍDEO
O die Greenland suporta o padrão DisplayPort 1.4 com HBR3, transporte multistream (MST), HDR e formatos de cores de alta precisão. Também suporta HDMI 2.0 de até 4K/60 Hz, 12 bits por canal de cor e codificação 4:2:0. O padrão de proteção de conteúdo HDCP é compatível com saídas HDMI® e DisplayPort.
Obviamente, a tecnologia Radeon™ FreeSync™ é suportada para jogos com taxa de atualização variável e, com o FreeSync 2™, mapeamento de tons de baixa latência do conteúdo HDR para o monitor conectado.
Assim como Polaris, uma GPU com chip Vega pode controlar até seis monitores conectados simultaneamente, mas expande o suporte para vários monitores em altas profundidades de bits, resoluções e taxas de atualização.
CURIOSIDADE: Para monitores HDR, o sistema operacional e os aplicativos podem optar por usar um formato de armazenamento de cores de maior precisão, com 16 bits de precisão de ponto flutuante por canal de cor – ou 64 bits por pixel, no total. Devido à largura de banda adicional necessária, esses modos têm restrições mais rígidas no número de monitores que podem ser conectados ao mesmo tempo. Vega 10 triplica o número de cabeças suportadas em 4K @ 60 Hz com formatos de pixel de 64 bits e adiciona suporte para dois modos de exibição adicionais que não são possíveis com Polaris 10.
Embora Polaris 10 possa suportar bem telas 4K para conteúdo SDR e algum conteúdo HDR, Vega 10 adiciona suporte para todo o material HDR usando formatos de pixel de 64 bits em 4K e 120 Hz.
O Vega 10 naturalmente inclui também as versões mais recentes dos mecanismos de codificação e decodificação de vídeo da AMD, como é o caso do VCE 4.0 e UVD 7.0, respectivamente. Assim como Polaris, Vega oferece decodificação baseada em hardware de perfil HEVC/H.265 main10 em resoluções de até 3840x2160 a 60 Hz, com cores de 10 bits para conteúdo HDR.
A decodificação dedicada do formato H.264 também é suportada em até 4K e 60Hz. Também pode decodificar o formato VP9 em resoluções de até 3840x2160 usando uma abordagem híbrida, onde os mecanismos de vídeo e shader colaboram para carregar o trabalho da CPU. O acelerador de codificação de vídeo também suporta os formatos mais populares da atualidade. Ele pode codificar HEVC/H.265 em 1080p @ 240 Hz, 1440p @ 120 Hz e 2160p @ 60Hz. A codificação de vídeo H.264 também é suportada em 1080p @ 120 Hz, 1440p @ 60 Hz e 2160p @ 60 Hz. A capacidade de codificar o formato H.264 em 3840x2160 em até 60 Hz é uma atualização da Polaris, que atinge 2160p @ 30 Hz.
CURIOSIDADE: Além disso, tais GPUs Radeon fornecem suporte de hardware exclusivo para virtualização SR-IOV, permitindo que a GPU seja compartilhada entre várias sessões de usuário em um ambiente virtualizado. Com isso, se adiciona uma nova peça crucial a este quebra-cabeça: compartilhar a codificação de vídeo do hardware e os recursos de aceleração de decodificação integrados à GPU. Com a Radeon Virtualized Encoding (RVE), as GPUs Vega 10 podem fornecer aceleração de codificação de hardware para até 16 sessões de usuário simultâneas. Esse recurso é especialmente adequado para hospedar sessões em aplicativos virtualizados multiusuário com cargas de trabalho graficamente intensas, como estações de trabalho remotas corporativas e jogos em nuvem.
Para o hardware GCN 5.0 implementado em APUs (ou seja, Picasso, Picasso-M, Raven e Raven-M), os antigos UVD e VCE foram substituídos pelo novo Video Core Next (VCN), em sua versão 1.0. A grande inovação foi substituir dois blocos de hardware (codificador e decodificador) por um único ASIC mais eficiente.

A GPU Vega 20 (die Moonshot) usa a arquitetura GCN 5.1 e é fabricada usando um processo de produção de 7 nm na TSMC, com um tamanho de matriz de 331 mm³ e uma contagem de transistores de 13.230 milhões.

Imagem 2 - Este é um Renoir-M, aplicado em algumas APUs Ryzen e que implementa a microarquitetura GCN 5.1
O Vega 20 oferece suporte a DirectX 12 (nível de recurso 12_1). Para aplicativos de computação GPU, o OpenCL versão 2.1 pode ser usado. Possui 4.096 unidades de sombreamento, 256 unidades de mapeamento de textura e 64 ROPs, tal qual a Vega 10, que faz uso da GCN 5.0.
Como podemos ver, a Vega 20 é apenas uma reestilização do produto anterior, isto é, o Vega 10 com GCN 5.0 fabricado usando um processo de produção de 14 nm na GlobalFoundries.
Exceto Vega 20, os demais são adaptadores gráficos de baixo desempenho e foram aplicados nas APUs Ryzen de quarta e quinta geração, como veremos adiante.
Os shaders na GCN 4.0 e 5.0
Assim como na GCN 5.0, as unidades de computação programáveis (shaders) no centro das GPUs Vega foram projetadas com a adição de um recurso chamado Rapid Packed Math. O suporte para matemática compactada de 16 bits dobra as taxas máximas de ponto flutuante e inteiro em relação às operações de 32 bits. Também reduz pela metade o espaço de registro, bem como a movimentação de dados necessária para processar um determinado número de operações. O novo conjunto inclui uma rica combinação de instruções de ponto flutuante e inteiro de 16 bits, incluindo FMA, MUL, ADD, MIN/MAX/MED, deslocamentos de bits, operações de empacotamento e muito mais.
Observe as semelhanças com a CU da GCN 4.0 (que foi apresentado lá no início):

Diagrama 6 - Talvez seja melhor abrir esta imegem em um novo separador para apreciar melhor
Para aplicativos que podem aproveitar esse recurso, o Rapid Packed Math (RPM) pode fornecer uma melhoria substancial no rendimento computacional e na eficiência energética. No caso de aplicações especializadas, como aprendizado e treinamento de máquina, processamento de vídeo e visão computacional, os tipos de dados de 16 bits são uma opção natural, mas há benefícios em obter mais operações de renderização tradicionais também. Os jogos modernos, por exemplo, utilizam uma ampla variedade de tipos de dados além do padrão FP32. Vetores normais / de direção, valores de iluminação, valores de cores HDR e fatores de mesclagem são alguns exemplos de onde as operações de 16 bits podem ser usadas.
Com suporte à precisão mista, Vega pode acelerar as operações que não se beneficiam de maior precisão, mantendo a precisão total para aquelas que o fazem. Assim, os aumentos de desempenho resultantes não precisam ocorrer às custas da qualidade da imagem.
Além do RPM, a NCU introduz uma variedade de novas operações inteiras de 32 bits que podem melhorar o desempenho e a eficiência em cenários específicos. Isso inclui um conjunto de oito instruções para acelerar a geração de endereços de memória e funções de hashing (comumente usadas em processamento criptográfico e mineração de criptomoedas), bem como novas instruções ADD/SUB projetadas para minimizar o uso de registros.
A NCU também suporta um conjunto de operações SAD (Soma de Diferenças Absolutas) inteiras de 8 bits. Essas operações são importantes para uma ampla gama de algoritmos de processamento de vídeo e imagem, incluindo classificação de imagens para aprendizado de máquina, detecção de movimento, reconhecimento de gestos, extração de profundidade estéreo e visão computacional. A instrução QSAD pode avaliar 16 blocos de 4x4 pixels por NCU a cada ciclo de clock e acumular os resultados em registradores de 32 ou 16 bits. Uma versão mascarável (MQSAD) pode fornecer otimização adicional, ignorando os pixels de fundo e concentrando a computação em áreas de interesse em uma imagem.
A potente combinação de inovações como Rapid Packed Math e as velocidades de clock aumentadas da NCU proporcionam um grande impulso no pico de rendimento matemático em comparação com produtos anteriores, com uma única GPU Vega 10 (GCN 5.0) capaz de exceder 27 teraflops ou 55 trilhões de operações inteiras por segundo.
CURIOSIDADE: Da primeira até a última geração da arquitetura GCN são 64 SPs em cada CU (exceto a GCN 2.0, onde contabilizaram a Unidade Escalar como SP também).
O Geometry Engine, DSBR e o Pixel Engine
Em suma, o "Geometry Processor" e o "Rasterizer", circuitos utilizados até a GCN 4.0 foram substituídos pelos blocos de hardware Geometry Engine e DSBR, que também passam a se comunicar com uma nova saída de rasterização denominada "Pixel Engine" (até a GCN 4.0 era RB, sigla para "Raster Block").
À medida que as telas de resolução ultra-alta e alta atualização se tornam mais difundidas, maximizar o rendimento de pixels está se tornando mais importante. Monitores com resoluções 4K, 5K e 8K e taxas de atualização de até 240 Hz estão aumentando drasticamente as demandas das GPUs atuais, e enquanto isso, os headsets VR apresentam um novo desafio para as taxas de pixels.
Os Pixel Engines na arquitetura Vega são construídos com o bloco de hardware Draw-Stream Binning Rasterizer (DSBR). Ele foi projetado para reduzir o processamento desnecessário e a transferência de dados na GPU - o que ajuda a aumentar o desempenho e a reduzir o consumo de energia. A ideia era combinar os benefícios de uma técnica já amplamente utilizada em produtos gráficos portáteis (renderização lado a lado) com os benefícios da renderização em modo imediato usando gráficos de PC de alto desempenho.
A renderização de modo imediato padrão funciona rasterizando cada polígono conforme ele é enviado até que toda a cena seja concluída, enquanto a renderização lado a lado funciona dividindo a tela em uma grade de blocos e, em seguida, renderizando cada bloco independentemente.
O DSBR percorre as primitivas em lote, um bloco por vez, determinando quais delas são total ou parcialmente cobertas pelo mesmo. A geometria é processada uma vez, exigindo um ciclo de clock por primitivo no pipeline.
Este projeto economiza largura de banda da memória no chip, mantendo todos os dados necessários para rasterizar a geometria de um bloco no cache L2. Os dados na memória do chip só precisam ser acessados uma vez e podem então ser reutilizados antes de passar para o próximo bloco. Vega usa um número relativamente pequeno de blocos e opera em lotes primitivos de tamanho limitado em comparação com aqueles usados em arquiteturas de renderização anteriores baseadas neste mesmo mecanismo. Essa configuração mantém os custos associados ao recorte e classificação gerenciáveis para cenas complexas, ao mesmo tempo em que oferece a maior parte dos benefícios de desempenho e eficiência.
CODIFICAÇÃO e DECODIFICAÇÃO de VÍDEO
Para o die Moonshot, a AMD simplesmente 'recauchutou' o UVD e o VCE da Vega 10, que foram implementados nas versões 7.2 e 4.1, respectivamente.
Para o hardware GCN 5.1 implementado em APUs, os antigos UVD e VCE foram substituídos pelo novo Video Core Next (VCN), em sua versão 2.0.
O Video Core Next, tecnologia lançada em Janeiro de 2018, é a marca da AMD para uma família de ASICs aceleradores de hardware para codificação e decodificação de vídeo e está integrado às GPUs e APUs desde os Ryzen 2200 / 2400G, que implementam o VCE 1.0.
Video Core Next suporta decodificação MPEG-2 , decodificação MPEG-4, decodificação VC-1, codificação / decodificação H.264/MPEG-4 AVC, codificação / decodificação HEVC e decodificação VP9.
O VCN 2.0 é implementado com produtos Navi (microarquitetura RDNA 1.0) e a APU Renoir. O conjunto de recursos permanece o mesmo da VCN 1.0.

Neste tópico trazemos algumas outras informações relevantes sobre as tecnologias detalhadas anteriormente...
Os Ryzen com GPU integrada
Em Janeiro de 2018, a AMD anunciou as duas primeiras APUs de desktop Ryzen com gráficos Radeon Vega integrados sob o codinome Raven Ridge. Eles foram baseados na arquitetura Zen de primeira geração. O Ryzen 3 2200G e o Ryzen 5 2400G foram lançados em Fevereiro.
Os Ryzen a partir da segunda geração fazem uso de um chip gráfico GCN 5.0 ou 5.1, a depender do produto. Conhecidos no mercado como APUs, incorporam um circuito de processamento gráfico denominado comercialmente como Vega 3, Vega 6, Vega 8, Vega 9 ou Vega 11, todos com diferentes configurações de shaders, TMUs, ROPs e clocks. De qualquer forma, as duas configurações de referência aplicadas nas APUs de segunda e terceira geração são:

Tabela 1 - As configurações dependem muito do produto. APUs com Vega 3, por exemplo, possuem apenas 192 unidades de sombreamento, contra 704 do modelo de referência
Talvez a configuração de referência mais comum da segunda e terceira geração dos Ryzen tenha sido a Raven / Raven-M:

Tabela 2 - Os Ryzen com a RX Vega 11 eram os unicos a portar todos os 704 shaders unificados disponíveis na espec. de referência. Aqueles com a RX Vega 8 tinham 512 sombreadores
A partir da quarta geração (que começou a surgir em meados de 2020), o Ryzen trouxe gráficos integrados Radeon Graphics baseados na microarquitetura GCN 5.1. Em geral tais adaptadores são definidos com o nome "Radeon Graphics xxxSP", onde o 'x' representa o número de Stream Processors (os shaders unificados, também conhecidos como sombreadores).
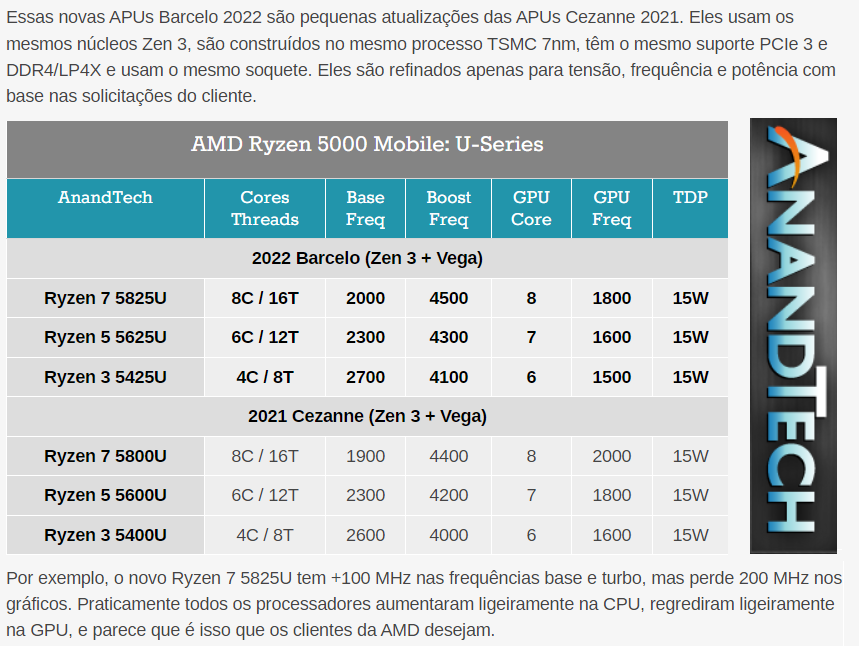
Complemento 1 - Tradução de uma matéria da Anandtech sobre as APUs Ryzen de quinta geração
Perceba que a tabela da Anandtech chama de "GPU Core" as Compute Units. De fato, são 8, 7 ou 6 Compute Units, a depender das especs. gerais, todavia, sabemos que as CUs abrigam, no total, até 512 sombreadores:

Tabela 3 - O Barcelo RG 448SP possui 448 sombreadores, enquanto o Cezanne RG 384SP abriga 384 shaders
Na quinta geração também surgiram os chips GCN 5.1 Lucienne e Renoir / Renoir-M:

Tabela 4 - O Renoir-M RG 320SP possui apenas 320 shaders, enquanto os demais, incluindo Lucienne variam entre 384 e 512 sombreadores, a depender do modelo
A partir do Ryzen 6000, a AMD utilizou a microarquitetura RDNA em suas APUs.
Infinty Fabric e FCLK?
Com a chegada dos Ryzen, a AMD lançou um novo sistema de modularidade para seus circuitos integrados super complexos. A CPU não têm um design monolítico, mas sim um pacote MCM, isto é, vários chips num mesmo susbtrato. Isso tem suas vantagens e desvantagens, mas o importante aqui é o termo Infinity Fabric e FCLK.
CURIOSIDADE: A tradução para Infinity Fabric é "Tecido Infinito", enquanto o FCLK é "Clock de Tecido".
Nos Ryzen ou Threadripper, você sempre verá vários chips menores e um central maior. Ao separar os chips, um melhor desempenho de fabricação (rendimento) pode ser alcançado em cada wafer, permitindo também colocar mais núcleos por processador. A filosofia monolítica da Intel pode ter vantagens no nível de interconexão entre núcleos, pois tudo está no mesmo die, entretanto, isso significa mais chips defeituosos e, consequentemente, uma produção mais custosa.
De qualquer forma, a AMD precisa de uma maneira de interconectar esses chips com rapidez e eficiência. É aí que entra a tecnologia de interconexão.
Cada chip é um CCX (Core Complex). É assim que a AMD chama suas unidades de processamento, cada uma composta por 4 núcleos, com seus níveis de cache L1 e L2, bem como um L3 compartilhado por esses quatro. Por outro lado, o agrupamento de vários CCXs é denominado CCD (Core Chiplet Dies), e esses pares são aqueles conectados pelo Infinity Fabric.
OBSERVAÇÃO: Não confudir o AMD CCD (Core Chiplet Dies) com os sensores de imagem CCD (Charge-Coupled Device). Quando vi a abreviação em matérias relacionadas às CPUs da AMD logo fui fazer a desambiguação, pois de fato duas siglas iguais e pouco dissertadas podem gerar alguma confusão. De qualquer forma, não existe qualquer relação entre estas tecnologias, apenas ocorreu a coincidência das abreviações terem as mesmas letras.
Além disso, o Infinity Fabric não é apenas interconectar de forma rápida e eficiente os diferentes CCXs para que eles possam se comunicar uns com os outros, ele também conecta esses núcleos com os controladores de RAM chips I/OD (Input Output Die) do substrato, que permitem a interface entre a CPU e a placa-mãe.

Diagrama 7 - Exemplo de como o Infinity Fabric é implementado
Como acontece com qualquer interface de comunicação sincronizada, uma frequência de clock é necessária para definir o ritmo de trabalho. Essa frequência é o que a AMD chama FCLK (Fabric Clock).
Na arquitetura Zen e Zen+, o FCLK não podia ser controlado de forma independente, estando associado à velocidade da RAM. Portanto, existem diferenças de desempenho ao optar por módulos de RAM DDR4 de frequência mais alta ou mais baixa. Por exemplo, em um Ryzen dessas primeiras gerações, módulos de pelo menos 3.000 ou 3.200 Mhz são necessários para não afetar significativamente o desempenho do Infinity Fabric.
Na Zen 2 isso mudou. O FCLK foi desacoplado do multiplicador de clock dos controladores de memória e pode ser controlado de forma independente (pelo menos nos chipsets X570), e isso pode ser feito a partir do setup do BIOS, podendo ajustar a velocidade do Infinity Fabric para que o sistema não sofra tanto quando a memória RAM estiver mais lenta. Já nos Ryzen 5000 (Zen 3), o FCLK é limitado a no máximo 2 Ghz (2000 Mhz). Isso corresponderia a 4000 Mhz na RAM (lembre-se que é Dual Data Rate, ou seja, DDR).
Se nos processadores o Infinity Fabric é o hub interno do chip, interligando blocos de hardware montados no substrato, nas GPUs baseadas em GCN 5.0 e 5.1 ocorre o mesmo. O Infinity Fabric é o hub interno que interconecta o processador gráfico, os controladores GDDR ou HBM, a interface PCIe, e os codificadores / decodificadores de vídeo, o bloco de hardware responsável por interfaces de vídeo (AMD EyeFinity) e motores DMA / CrossFire XDMA.
O chip Vega 10 já permite um controle mais refinado sobre as frequências operacionais com a adição de um terceiro domínio de clock (um PLL com multiplicador à parte), além do núcleo gráfico e dos domínios de memória, para sua interconexão em nível de SoC Infinity Fabric. Com a GCN 5.0 e 5.1, esta interface já é sincronizada separadamente do núcleo gráfico. Como resultado, a GPU pode manter altas velocidades de clock no domínio Infinity Fabric para facilitar transferências rápidas de dados DMA em cargas de trabalho que apresentam pouca ou nenhuma atividade gráfica, como transcodificação de vídeo. Enquanto isso, a GPU pode manter a velocidade do núcleo gráfico reduzida, economizando energia sem comprometer o desempenho na tarefa em questão.
CURIOSIDADE: Para aproveitar esse tipo de capacidade dinâmica de ajuste de clock e energia, chips Vega possuem um novo recurso conhecido como "identificação ativa de carga de trabalho". O software do driver pode identificar determinadas cargas de trabalho com necessidades específicas – como jogos em tela cheia, computação, vídeo ou VR – e notificar o microcontrolador de gerenciamento de energia de que tal processo está ativo. O microcontrolador pode então ajustar os vários domínios do chip de forma adequada para extrair a melhor combinação de desempenho e consumo de energia.
Utilizando a mesma interface de comunicação interna para CPUs e GPUs a AMD aumenta a modularidade e barateia custos de implementação. Se antigamente fazia-se uso do Front Side Bus (FSB) para conectar os núcleos da CPU aos controladores de RAM e demais circuitos no chipset Ponte Norte, hoje este chipset está dentro da CPU e a conexão entre os circuitos pode ser feito com uma interface moderna e de alta taxa de transferência!

Este texto foi construído com base no Whitepaper da arquitetura GCN 4.0 e da GCN 5.0. Você pode acessar estes PDFs abaixo:
No próximo 'episódio' da série, um tour pelas arquiteturas Turing e Ampere, da nVidia.
Para dúvidas, correções ou sugestões, mande um e-mail para hardwarecentrallr@gmail.com.
FONTES e CRÉDITOS
Texto: Leonardo Ritter;
Diagramas: GPU-Z; Leonardo Ritter;
Fontes: GPU-Z, AnandTech; todohardware.pt; golem.de; documentos da AMD listados anteriormente; Wikipedia (somente artigos com fontes verificadas!).
Comments